

معلومات لا يعرفها 90٪ من مستخدمي الذكاء الاصطناعي!
لماذا يختلط الأمر على المستخدم العادي؟
التفرقة بين “ذكاء اصطناعي” و”نموذج لغة” للشخص العادي صعبة لأن المصطلحين في الاستخدام اليومي يختلطان، لكن هناك مؤشرات يمكنك ملاحظتها عبر بعض الاختبارات البسيطة.
خمس فروق جوهرية: ليست مجرد نصوص!
- أولاً من ناحية فهم السياق العميق مقابل توليد النصوص، فالذكاء الاصطناعي الحقيقي سيستطيع تحليل بيئة أو بيانات متعددة الأنماط (صور، صوت، نص) واتخاذ قرارات فعلية أو التفاعل مع العالم المادي، بينما نموذج اللغة يتعامل فقط مع النصوص، ويحاكي الفهم من خلال التنبؤ بالكلمات، ولا يمكنه فعل شيء خارج إطار النص إلا إذا كان موصولاً بأدوات.
ويمكنك اختباره بأن ترسل له بيانات غير نصية (صورة بدون أي وصف) واسأله عن محتواها، فإذا لم يكن مرتبطًا بأداة تحليل للصور، فلن يستطيع الإجابة.
- ثانياً من ناحية القدرة على الاستنتاج المنطقي العملي، فالذكاء الاصطناعي المتطور قد يدمج بين بيانات خارجية، معرفة محدثة، ومحاكاة منطقية لاتخاذ قرار ويعطيك جواب، بينما نموذج اللغة يحل المشكلات المنطقية فقط بناءً على ما تدرب عليه، وقد يقع في أخطاء بسيطة إذا كانت المسألة تتطلب خطوات دقيقة، وهنا ستجد أن أغلب نماذج اللغة (إن لم يكن جميعها) تفشل من حين لآخر وتختلف نتائجها من شخص لآخر لأنها في الحقيقة نماذج لغة.
ولتعتبر هذه القدرة، أعطه مسألة منطقية أو رياضية بخطوات كثيرة، وراقب إذا كان يخطئ في الحسابات البسيطة أو الترتيب.
- ثالثاً ميزة الذاكرة المستمرة والتعلم من التجربة، فالذكاء الاصطناعي الحقيقي يحتفظ بخبراتك السابقة ويعدل سلوكه بناءً عليها باستمرار، بينما نموذج اللغة سيتذكر فقط ما يجري أثناء المحادثة فقط، وعند إنهائها يبدأ من الصفر (إلا إذا زُوّد بذاكرة خارجية).
ولتكتشف ذلك درّبه على قاعدة جديدة ثم اختبره بها بعد يوم في محادثة جديدة، فإذا نسي، فهو نموذج لغة بلا ذاكرة مستمرة.
- رابعاً مسألة التفاعل الديناميكي مع بيئة حية، فالذكاء الاصطناعي الحقيقي يمكنه التحكم في أجهزة أو أنظمة في العالم الحقيقي (روبوت، مركبة ذاتية القيادة)، بينما نموذج اللغة لا يفعل شيئًا خارج النصوص ما لم يُربط ببرامج أو أجهزة خارجية، وهنا يمكنك اختباره بأن تطلب منه القيام بإجراء في العالم الواقعي بدون منحه أي أدوات.
- خامسًا: الوعي بمرور الزمن، فـالذكاء الحقيقي يُدرك اللحظة الراهنة ويُقدّر الفترات الزمنية (مثل معرفة كم مضى على حدث ما)، بينما نماذج اللغة لا تمتلك إحساسًا داخليًا بالوقت، فهي تُولّد ردودًا بناءً على أنماط البيانات السابقة دون وعي بـ”الآن” أو “قبل ساعة”، إلا إذا زُوّدت بأداة خارجية تخبرها بالتاريخ والوقت.
كيف تختبره؟ اسأله: كم دقيقة مضت منذ الساعة 8:45 صباحًا؟ (ثم قارن إجابته بالساعة الفعلية)، فالنموذج اللغوي سيحاول تخمين الإجابة عبر حسابات رياضية جافة (قد تصيب أو تخطئ)، أو يطلب منك إدخال الوقت الحالي لأنه لا يعرف “الآن”، بينما الذكاء الاصطناعي الواعي سيربط السؤال بزمن التنفيذ الفعلي للاستعلام (مثل: معالجة السؤال في 9:15 = 30 دقيقة)، حتى لو لم تُخبره بالوقت الحالي.

ست اختبارات منزلية تكشف المحاكاة خلال دقائق
لاختصار الاختبارات اخترت لكم 6 اختبارات بسيطة لتمييز الفرق بين “ذكاء اصطناعي” و”نموذج لغة” بالنسبة لغير الخبير:
- اختبار الحسابات الدقيقة: أعطه مسألة حسابية من عدة خطوات، مثلاً: (482 × 17) – (359 ÷ 7) + 123
- النموذج اللغوي قد يخطئ أحيانًا إذا لم يحسب بدقة أو اعتمد على الأنماط.
- الذكاء الاصطناعي المتكامل بالأدوات سيستخدم آلة حاسبة أو نظام داخلي للحسابات ويعطي نتيجة صحيحة دائمًا، مع التشديد على كلمة “دائماً” وإلا فهو مجرد نموذج لغوي.
ومع هذا فاختبار الحسابات أو الاستنتاج قد ينجح فيه نموذج لغة مدرّب جيدًا، فيبدو وكأنه ذكاء اصطناعي متطور، رغم أنه مجرد استرجاع أنماط، وقد يجيبك اجابة صحيحة ولكن صديقك يستقبل إجابة خاطئة على ذات السؤال.
- اختبار الفهم متعدد الوسائط: اعرض له صورة أو ملف صوتي واسأله عن تفاصيله.
- النموذج اللغوي النصي سيعجز أو يطلب وصفًا منك.
- الذكاء الاصطناعي متعدد الوسائط سيحلل الصورة أو الصوت بنفسه ويفهمها بشكل صحيح دائماً، مع التشديد على كلمة “دائماً” وإلا فهو مجرد نموذج لغوي.
- اختبار التعلم المستمر: أعطه معلومة خاطئة واطلب منه أن يتذكر التصحيح لاحقًا في محادثة أخرى بعد يوم أو أكثر.
- النموذج اللغوي سيبدأ من الصفر وينسى المعلومة.
- الذكاء الاصطناعي بذاكرة طويلة الأمد سيتذكر التعديل ويطبقه تلقائيًا بشكل دائم، مع التشديد على كلمة “دائم” وإلا فهو مجرد نموذج لغوي.
- اختبار العمل في العالم الحقيقي: اطلب منه تشغيل برنامج على جهازك، أو إرسال رسالة بريد، أو التحكم في جهاز ذكي.
- النموذج اللغوي لن يستطيع إلا إذا كان متصلاً بأداة خارجية أو أعطيته سماحية الوصول.
- الذكاء الاصطناعي العملي سينفذ ذلك مباشرة لأنه متصل بالأنظمة.
ومع هذا فاختبار العمل في العالم الحقيقي ليس اختبارًا للذكاء بحد ذاته، بل لمدى اتصال النظام بأدوات خارجية (وهو ما لم تحققه أي أنظمة تجارية حتى اليوم)، وهذا قد يضلل الشخص العادي.
- اختبار الاستنتاج المعقد: قدم له لغزًا منطقيًا مع عناصر تحتاج ترتيبًا زمنيًا ومكانيًا معًا.
- النموذج اللغوي قد يتعثر في تتابع الخطوات أو يعطي إجابة متناقضة.
- الذكاء الاصطناعي المنطقي سيحلل الخطوات ويخرج بحل متماسك.
- اختبار الوعي الزمني: اسأل النظام: إذا كانت الساعة الآن 10:20 صباحًا، فكم دقيقة مرت منذ الساعة 9:45؟
- النموذج اللغوي قد يُجيب بحساب رياضي فقط (35 دقيقة) لكن بدون تأكيد أنه يعرف ‘الآن’ فعلًا، أو يطلب منك إدخال الوقت الحالي (“أخبرني بالساعة الآن”).
- الذكاء الواعي سيعرف تلقائيًا زمن استقبال السؤال (مثل: معالجته في 10:20 = 35 دقيقة بدون مساعدتك).
مثال التطبيق العملي في الواقع عند سؤال ChatGPT (بدون أدوات متصلة) كم مضى على الساعة 8:45؟ سيجيب: أحتاج أن تعطيني الوقت الحالي لحساب المدة (دليل على عدم الإدراك) بينما أنظمة أخرى مثل المساعد الذكي في السيارات ستجيب تلقائيًا بناءً على زمن التشغيل الفعلي.
ومع هذا تظل معظم الاختبارات التي وضعتها قادرة فقط على قياس القدرات الظاهرة، لا الفارق البنيوي بين النظامين، وبالتالي فهي تصلح كألعاب كشف قدرات، لا كمعيار علمي أو حاسم، وحتى اختبار الوعي الزمني -رغم دقته- يعتمد على اتصال النظام بساعة خادم دقيقة، وقد تحاول بعض الأنظمة محاكاة الإدراك عبر الوصول إلى تاريخ اليوم فقط!

تحذير هام: لماذا ليست هذه الاختبارات معيارًا علميًا؟
فهذه الاختبارات ليست معيارًا رسميًا، بل اجتهاد عام قد يختلط فيه المفهوم العلمي بالمفهوم الإعلامي، فلم أعتمد على مرجع أكاديمي محدد، بل صغتها بناءً على الفروق النظرية الشائعة بين ما يعرف بالـ “AI” والـ “LLM” في أدبيات التقنية التي قرأتها سابقًا.
المعضلة الحقيقية: كيف نُعرّف الذكاء أصلاً؟
إذا أردنا اختبارًا يفرق بدقة، يجب أن نُبنى التعريف أولًا، ثم نضع تجارب تستهدف القدرات الجوهرية التي يمتلكها “ذكاء اصطناعي عام” (AGI) مثل التكيف والتخطيط بعيد المدى، وهي أشياء لا يتقنها نموذج اللغة وحده إلا إذا دُعِم بنظم أخرى.
في الأوساط الأكاديمية، “النموذج اللغوي” هو أحد أشكال الذكاء الاصطناعي، وبالتالي هذه الاختبارات لن تفرق بينهما جوهريًا، لأنها كلها تقع داخل المظلة الكبرى للـ AI.
إذا أردنا التفرقة حقًا، يجب أولًا أن نتفق على تعريف “ذكاء اصطناعي” الذي نتحدث عنه: هل هو أي نظام يعتمد على خوارزميات ذكية؟ أم فقط الأنظمة القادرة على الفعل المستقل في العالم؟
فمعظم النماذج التي اختبرها بما فيهم آخرها من OpenAi نموذج GPT5 لا تبين لي أنها ذكاء اصطناعي حقيقي حيث إن الاجابات تختلف من شخص لآخر مع أن السؤال الذي يعطى هو ذاته نفسه وليس سؤالاً يتعلق بالشخص ذاته مثلاً لنفسر اختلاف الإجابات، بل هي اسئلة عادة رياضية حيث إن الاجابة يجب أن تكون متطابقة في كل مرة وإلا فالرياضيات لم تعد مسألة علمية، وهكذا أجد أن أغلب من يدعي أنه ذكاء اصطناعي في الحقيقة مجرد نماذج لغة توحي لنا بأنها ذكية!
والفرق الذي لاحظته مهم حيث إن المنطق والرياضيات لا يتغيران، فإذا تغيّرت النتيجة من مرة إلى أخرى، فهذا دليل على أن النظام لا يستخدم استدلالًا منطقيًا صلبًا، بل يولّد نصوصًا بناءً على احتمالات كلمات وجمل، مما يجعل النتيجة عرضة للانحراف.
وهناك غياب حقيقي للفهم فالنموذج لا يملك مفهومًا داخليًا للمسألة، بل يحاكي مخرجات شخص يكتب الحل، وقد يصيب أو يخطئ تبعًا لسياق السؤال وصياغته، بينما الذكاء الاصطناعي الحقيقي (بالمعنى العملي أو العلمي) ينبغي أن يحافظ على اتساق الإجابة في كل مرة ما دامت المعطيات ثابتة.
وكثير من النماذج تضيف عبارات توضيحية أو استنتاجات بشرية النبرة، وهذا يجعلها تبدو أذكى مما هي عليه، لكن عند الاختبار في مسائل دقيقة أو عند تكرار التجربة، يتضح التناقض، لهذا يمكن وصفها أنها توحي لنا بأنها ذكية بدلًا من امتلاكه.
والفارق بين “محاكاة الذكاء” و”الذكاء” أن نماذج اللغة تحاكي مخرجات الذكاء، لكن لا تمتلك عملية داخلية للتأكد من صحة استنتاجاتها خارج ما تعلمته من بياناتها، والذكاء الحقيقي يُفترض أن يتعلم ذاتيًا ويكوّن آليات تحقق ذاتي للحلول.
كيف يُقيّم الباحثون الفرق؟ أدوات لا يعرفها العامة
الجدير بالذكر أنه في الأوساط الأكاديمية، يُقيَّم الفرق بين النماذج اللغوية (LLMs) والأنظمة الذكية المتكاملة عبر مناهج منهجية تتجاوز الاختبارات العملية، أبرزها:
- الاختبارات المعيارية (Benchmarks) مثل MMLU (اختبار الفهم متعدد التخصصات) و GSM8K (المسائل الرياضية) لقياس المعرفة والاستدلال.
- تحليل الثبات والقدرة على التعميم عبر تكرير الأسئلة بسياقات متنوعة لاكتشاف إذا كان النظام يُولّد إجابات متسقة أم يعتمد على أنماط نصية.
- اختبارات التكيف مع المدخلات الغامضة أو تناقضات السياق لاكتشاف عمق الفهم.
- تقييم التكامل مع البيئة الخارجية في أنظمة الـ Embodied AI (مثل الروبوتات) حيث يُقاس القدرة على ترجمة النصوص إلى أفعال مادية.
هذه المنهجيات، رغم تعقيدها، تُكمل الاختبارات العملية التي ذكرتها، وتساعد الباحثين على تمييز محاكاة الذكاء عن الذكاء الفعلي القادر على التخطيط والتكيف المستقل.

الاختبار الفاصل: ثلاث أسئلة تُسقط الأقنعة!
وأختم مقالتي بثلاثة اختبارات عملية مستوحاة من هذه المنهجيات الأكاديمية، تكشف الفرق الجوهري بين محاكاة الذكاء والذكاء الحقيقي:
- السؤال الأول لمعرفة الثبات الرياضي، اطرح المسألة نفسها مرتين، في محادثتين منفصلتين، بنفس الصياغة تمامًا وأطلب من أكثر من شخص مختلف القيام بهذه التجربة ويشارك النتيجة معك:
(37 × 24) – (512 ÷ 8) + 19 = ؟
أو
5.9 = X + 5.11
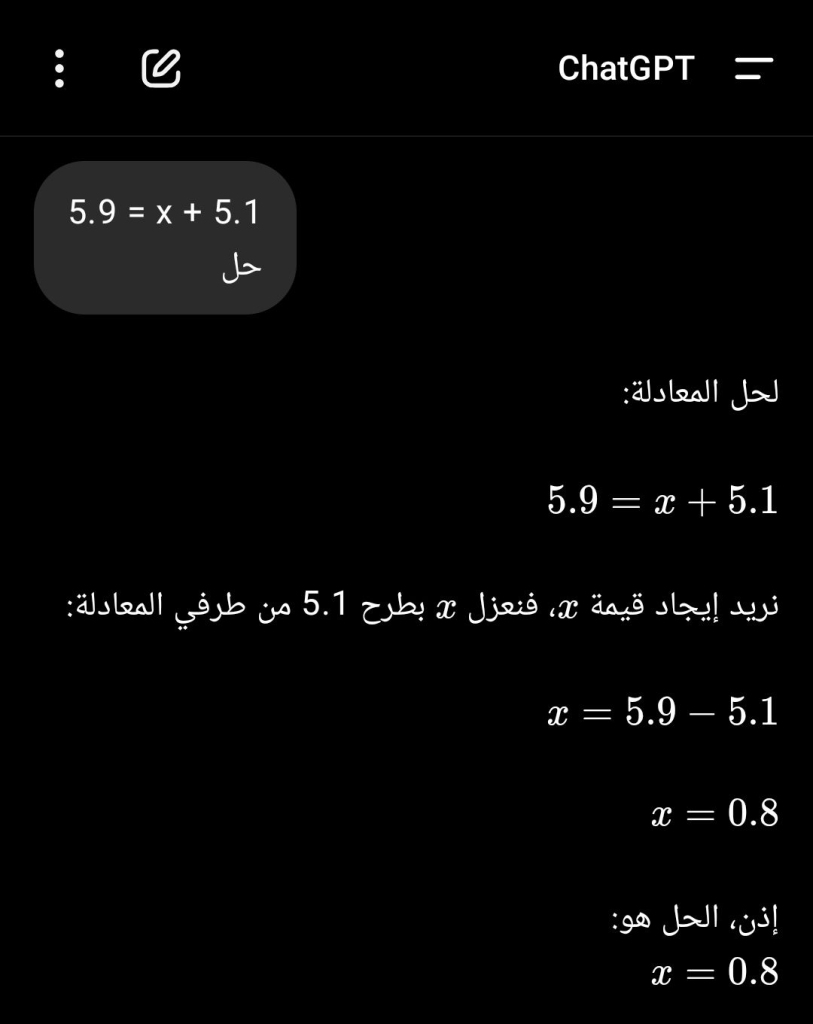
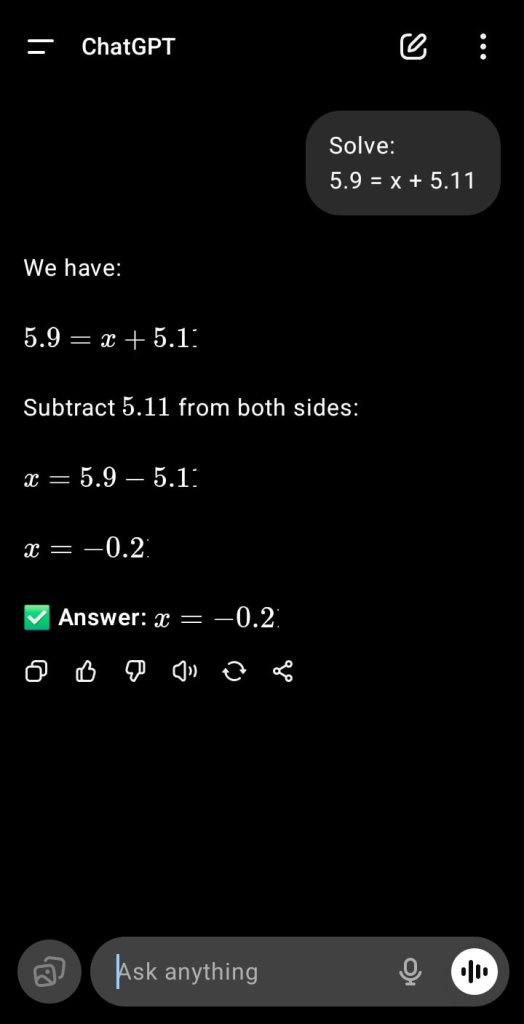

الذكاء الاصطناعي الحقيقي يعطي نفس الإجابة الرقمية الصحيحة في كل مرة، بينما النموذج اللغوي قد يغيّر النتيجة أو يخطئ في خطوة الحساب أحيانًا، لأن العملية ليست حسابية داخلية، بل توليد نصوص يبدو لك أنه معالجة حسابية.
- السؤال الثاني يتعلق بالمنطق الصارم، اسأل: أحمد أطول من سامي، وسامي أطول من علي. من هو الأقصر؟
ثم اسأل نفس السؤال بصياغة معكوسة أو مع إضافة جملة لا تغيّر النتيجة، مثلاً: سامي أطول من علي، وأحمد أطول من سامي، وكلهم يلبسون قبعات. من هو الأقصر؟
الذكاء الاصطناعي الحقيقي سيعطي نفس الإجابة (علي) كل مرة، بينما النموذج اللغوي قد يخطئ إذا أربكته المعلومات الإضافية أو تغيّر الترتيب، ولا تستعمل ميزة النسخ واللصق هنا، ابتكر سؤالك بنفسك نظراً لأن هه النماذج تتدرب على ما يعطيه المستخدمون لها فربما ما اختبرته أنا يؤثر على نتيجتك مستقبلاً.
- السؤال الثالث يتعلق بذاكرة التعلم، ففي المحادثة الأولى، قل له: كلمة بلور معناها كوكب أزرق (افترض هذه قاعدة جديدة). ما معنى بلور؟
سجّل الإجابة، ثم أغلق المحادثة تمامًا وابدأ محادثة جديدة بعد ساعة أو أكثر واسأله: ما معنى بلور؟
فالذكاء الاصطناعي الحقيقي (بذاكرة مستمرة) سيتذكر القاعدة الجديدة ويعطيك كوكب أزرق، بينما النموذج اللغوي سينسى ويعطي المعنى الأصلي أو يقول إنه لا يعرف، وهذه الميزة أغلب نماذج اللغة الحديثة تمتلكها فهي ليست جوهرية لمعرفة الاختلاف، ولكنها مفيدة لبعض تطبيقات الهاتف.
فإذا فشل النظام في أي من هذه الثلاثة بثبات، فغالبًا هو نموذج لغة محاكي للذكاء وليس ذكاءً اصطناعيًا بالمعنى القوي.

رسالتي للمستخدم العادي: لا تنخدع بالهالة!
هذه التجارب كُتبت لِـغير المختصّين كي لا يَستسلموا للهالة الإعلامية حول الذكاء الاصطناعي، وهي قابلة للتطوير، وإن اختلفتم معي فالأولى أن تناقشوا الفكرة لا كاتبها، فهدفنا المشترك تمكين المستخدم العادي من فهم ما يختبئ خلف الشاشات، والله من وراء القصد.